Captain's Log: Diving into our scheduling design
TL;DR: Schedules are simple — until they're not. Let's talk about how we architected an on-call scheduling system that works for modern businesses.

By Robert Ross on 12/5/2023

On-call scheduling is tricky. Like, really tricky. It was one of the scariest parts when we decided to build a modern alerting system earlier this year. We knew we couldn't cut any corners on Day One of our release because it needed to be a fully loaded feature for someone to realistically use our product (and replace an incumbent).
This meant including windowed restrictions, coverage requests, and simple to complex rotations. And after many months of seeing our scheduling design in the wild, I'm excited to give a detailed technical overview of how it works. Buckle up!
Schedules != Shifts
At its core, an on-call schedule is a list of shifts ordered by their start and end times. And that’s exactly how we modeled the database for on-call schedules. It looks like this:
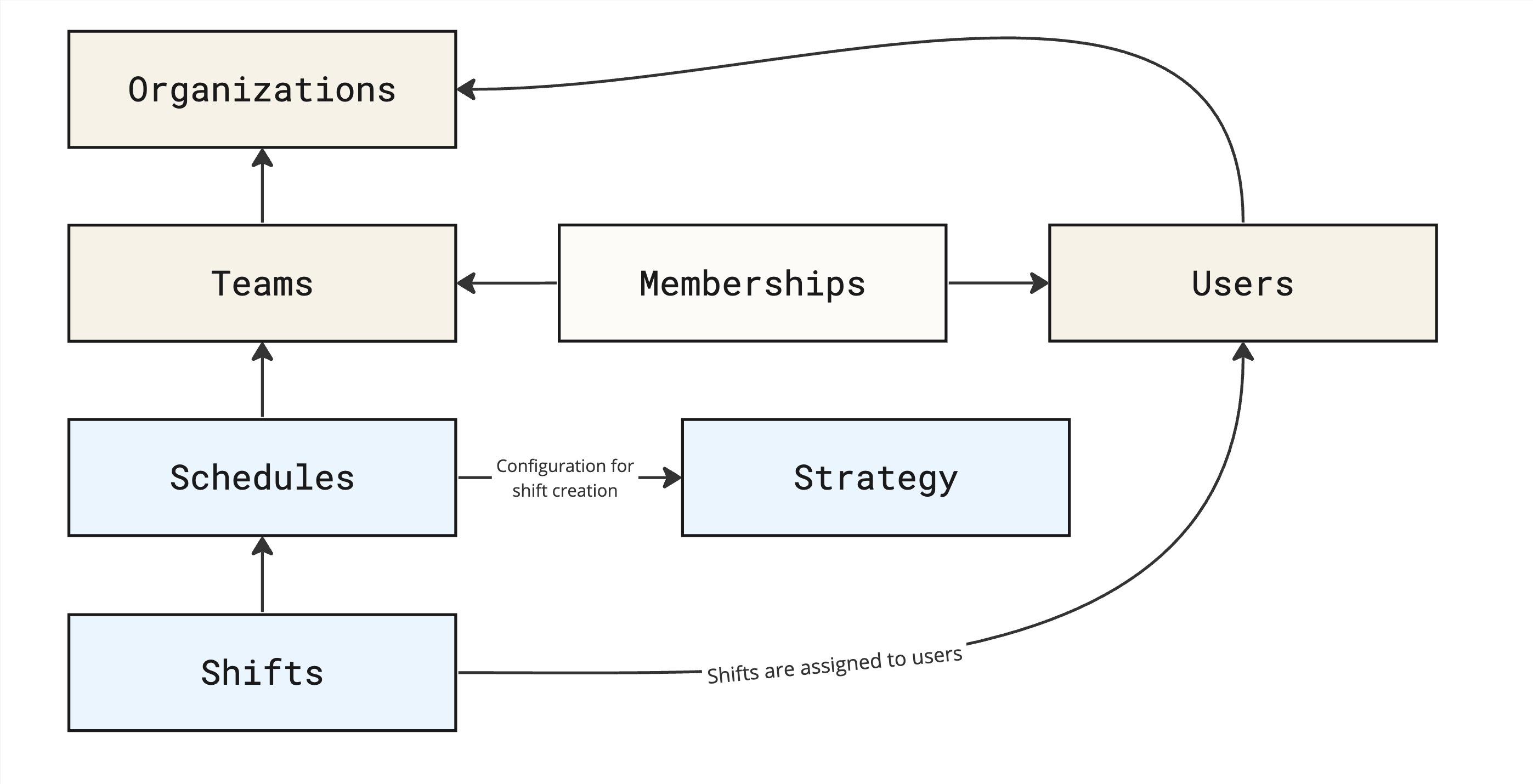
We chose this approach because:
It allows reassigning a shift to another user seamlessly without screwing up the entire rotation.
We can create one-off changes on a schedule that is outside of a strategy (i.e. maintenance window on-call).
It makes summarizing how much time someone has been on-call drop-dead simple in analytics.
The purpose of shifts
In Signals, a shift is a simple record that stores a start and end time and the on-call user during that period. We create shifts based on a schedule's strategy and allow users to create ad-hoc shifts. Here is a first look at the page that defines how we create shifts for being on-call:
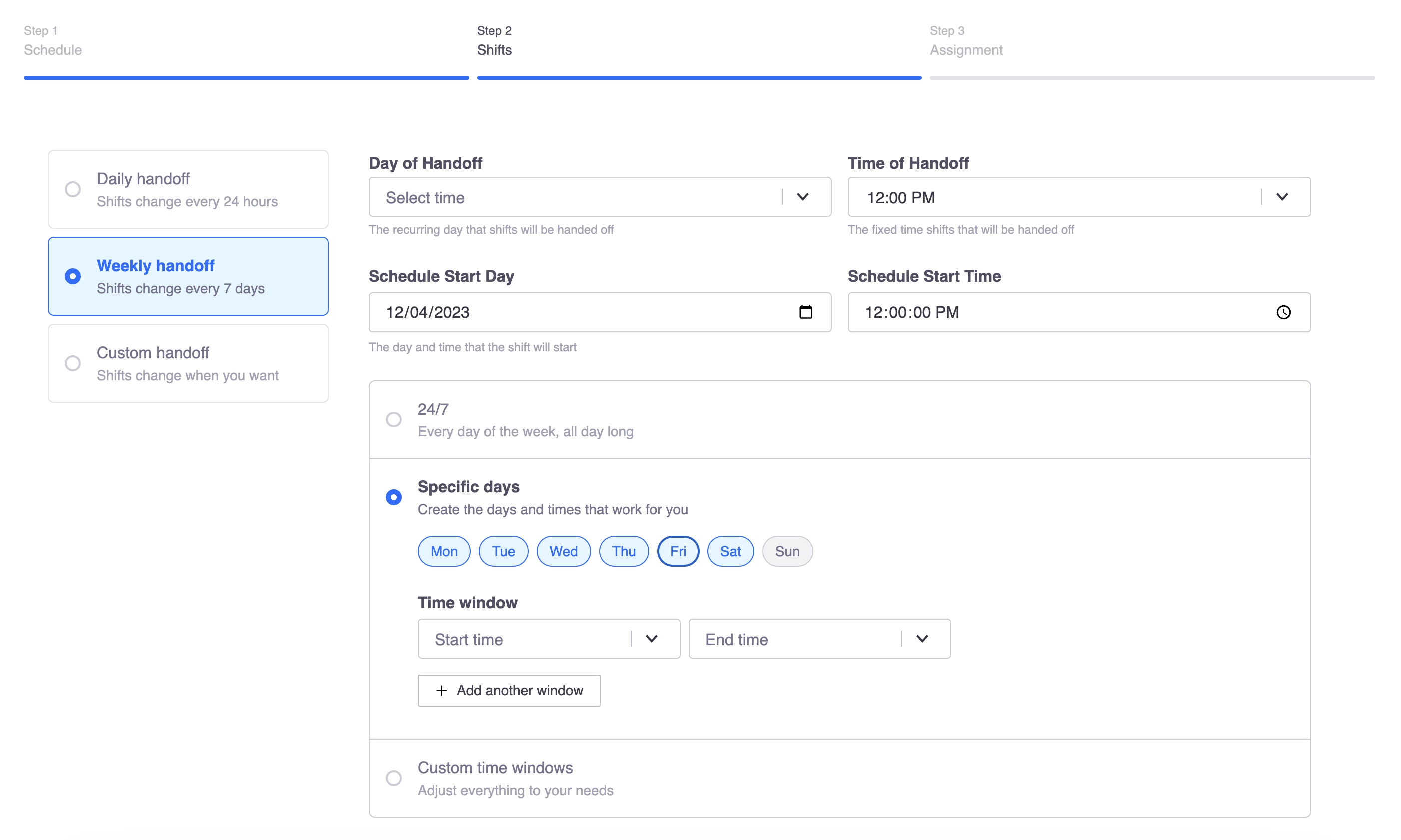
When a schedule is created, a background task is scheduled to create every shift based on the strategy selected and any restrictions applied. This task usually takes a few seconds but creates shifts for the next six months. The same job will continue to create shifts every day for every schedule to guarantee there are always at least six months of shifts created.
Restrictions
One of the most complex parts of creating shifts for an on-call schedule is masking the start and end times with a defined restriction. Shift restrictions are a necessary part of an on-call system because they enable teams to:
Create follow-the-sun rotations
Have off-hour-only shifts
Create shifts with lunch breaks built in
For example, below is a schedule restricted to only Monday-Friday, with a lunch break built into the middle.
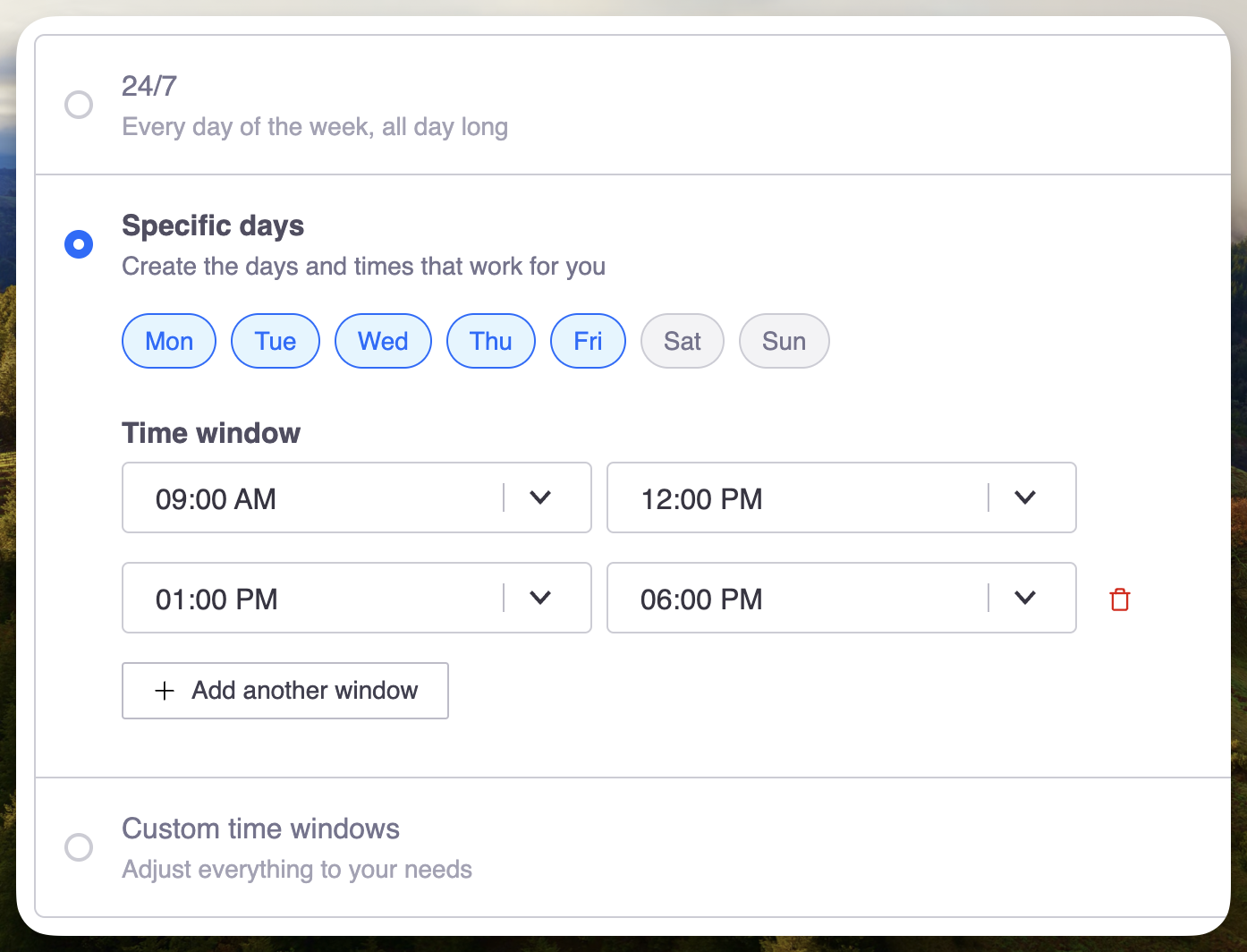
This creates several shifts for the given windows:
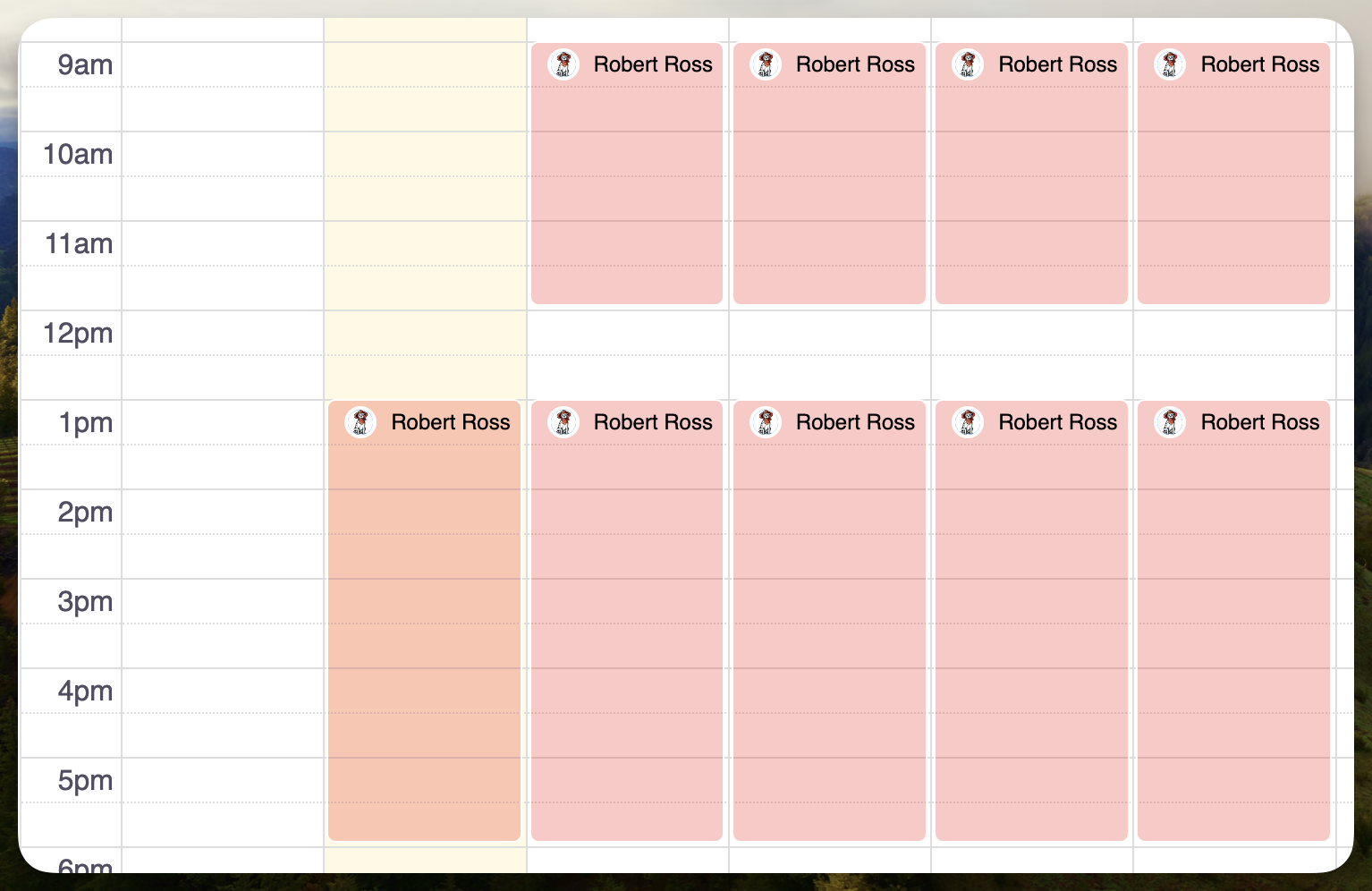
How we approach coverage requests
Any great on-call software should support overriding upcoming shifts. Because we separated shifts and schedules, this feature was far more straightforward to implement than if we were to overload the schedule logic itself.
When someone requests coverage (using Slack or the UI), we split the shift they're requesting coverage for into two shifts (or three, if they're in the middle of a shift) and allow someone else to claim the new shift period. Here's a snippet of the code in production that does this:
# If the shift is contained entirely within the provided time period,
# we can just set the coverage request on the existing shift and move on:
#
# Request: |-----------| |-------------|
# Shifts: |-----------| |-----------|
# Result: |-----X-----| |-----X-----|
coverage_result = if start_time <= shift.start_time && end_time >= shift.end_time
updater = add_child_writer(Signals::OnCallShiftUpdater.new(shift, **actor_and_organization))
updater.update!(coverage_request: reason)
elsif start_time <= shift.start_time && end_time < shift.end_time
# If the provided period overlaps with only the start of the shift, we
# split the shift into two and set the coverage request on the left one:
#
# Request: |---| |--------|
# Shifts: |-----------| |-----------|
# Result: |-X-|-------| |--X--|-----|
request_coverage_for_beginning_of_shift!(shift, start_time, end_time, reason)
elsif start_time > shift.start_time && end_time >= shift.end_time
# If the provided period overlaps with only the end of the shift, we
# split the shift into two and set the coverage request on the right one:
#
# Request: |---| |--------|
# Shifts: |-----------| |-----------|
# Result: |-------|-X-| |-----|--X--|
request_coverage_for_end_of_shift!(shift, start_time, end_time, reason)
elsif start_time > shift.start_time && end_time < shift.end_time
# If the shift extends past the provided period in both directions, we split
# the shift into three and set the coverage request on the middle one:
#
# Request: |-----|
# Shifts: |-----------|
# Result: |--|--X--|--|
request_coverage_for_middle_of_shift!(shift, start_time, end_time, reason)
end
Loading the configuration
As we wrote in the first Captain's Log, we're very focused on resiliency regarding Signals. Laddertruck, the application where our API and UI live for configuring on-call schedules, can fail, and Signals can still be dispatched to on-call engineers.
We accomplish this by serializing schedules and their shifts into protocol buffer messages and storing that in object storage. Here is a snippet from that message definition:
message OnCallSchedule {
message Shift {
string id = 1;
optional string user_id = 2;
google.protobuf.Timestamp start = 3;
google.protobuf.Timestamp end = 4;
}
string id = 1;
string organization_id = 2;
string name = 3;
repeated Shift shifts = 4;
}
When a schedule is targeted by an escalation policy (or other harness) to send an alert to an on-call engineer, we build an interval tree for all the shifts in the schedule. We're using the intervalst Go package in Siren to create this data structure that enables us to rapidly find the current shift and, therefore, the user we need to notify of an incident.
package dispatch
import (
"fmt"
"sync"
"time"
"github.com/firehydrant/siren/types"
"github.com/rdleal/intervalst/interval"
)
var ErrNoShiftFound = fmt.Errorf("no shift found")
type SearchableSchedule struct {
sync.RWMutex
Schedule *types.OnCallSchedule
searchTree *interval.SearchTree[*types.OnCallSchedule_Shift, time.Time]
}
var cmpFn = func(t1, t2 time.Time) int {
switch {
case t1.After(t2):
return 1
case t1.Before(t2):
return -1
default:
return 0
}
}
func (s *SearchableSchedule) FindShift(lookupTime time.Time) (*types.OnCallSchedule_Shift, error) {
if s.searchTree == nil {
err := s.buildTree()
if err != nil {
return &types.OnCallSchedule_Shift{}, err
}
}
s.RLock()
shift, ok := s.searchTree.AnyIntersection(lookupTime, lookupTime)
s.RUnlock()
if !ok {
return &types.OnCallSchedule_Shift{}, ErrNoShiftFound
}
return shift, nil
}
func (s *SearchableSchedule) buildTree() error {
s.Lock()
defer s.Unlock()
s.searchTree = interval.NewSearchTree[*types.OnCallSchedule_Shift](cmpFn)
for _, shift := range s.Schedule.GetShifts() {
err := s.searchTree.Insert(shift.GetStart().AsTime(), shift.GetEnd().AsTime(), shift)
if err != nil {
return err
}
}
return nil
}
This code enables us to route an alert to the on-call engineer when a Signal comes in based on the current list of shifts for a schedule. And it's lightning fast.
Wrapping up
By separating shifts from schedules, we've made a robust on-call system included in the launch of our open beta for Signals, coming the first half of this month. This design and architecture have been in production for months now, and it continues to impress me with its simplicity and effectiveness.
See Signals in action
Experience a cost-effective alerting tool designed specifically for how modern DevOps teams work.
Join the waitlist