Featured
March 18, 2024
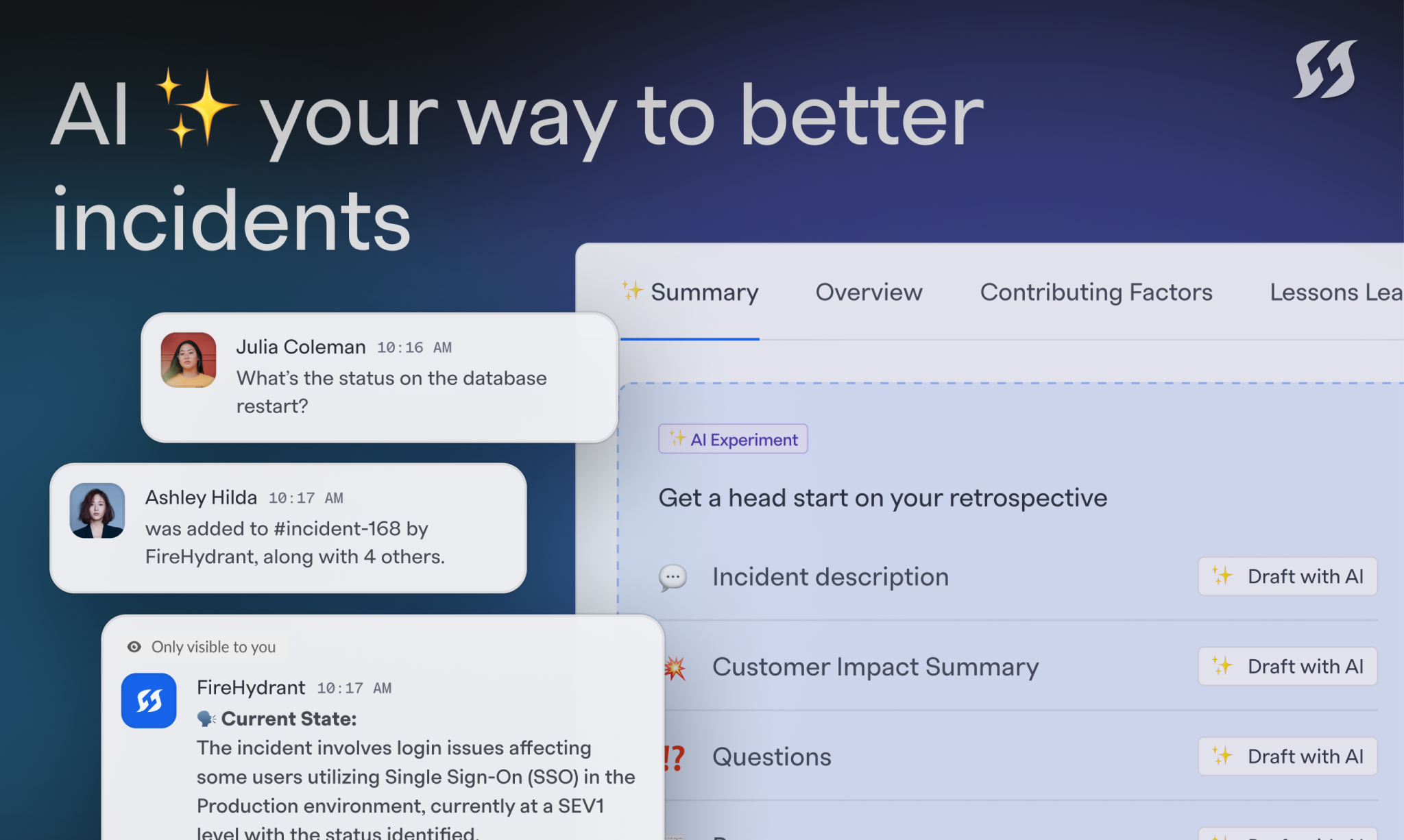
FireHydrant is now AI-powered for faster, smarter incidents
Power up your incidents with auto-generated real-time summaries, retrospectives, and status page updates. And that’s just the beginning.
Featured
March 18, 2024
Power up your incidents with auto-generated real-time summaries, retrospectives, and status page updates. And that’s just the beginning.
By Danielle Leong
3/11/2024

By Robert Ross
3/6/2024

By Robert Ross
2/29/2024

By Milan Thakker
2/14/2024
By The FireHydrant Team
2/13/2024

By Robert Ross
1/18/2024
By Robert Ross
12/8/2023

By Robert Ross
12/5/2023
By Jouhné Scott
11/30/2023

By Stephanie Gonzalez
11/20/2023
By Robert Ross
11/20/2023
By Robert Ross
11/8/2023
Create a free account and start managing your incidents today
October releases saw greater customization of how you view and share incident data to suit your specific needs, and refreshed and fired-up status pages.
By Joel Smith
10/27/2023
It's high time we acknowledge that the way we’re running alerting is stuck in time. To move forward, we must lift the curtain on areas that have to evolve and embrace the new principles of incident alerting.
By Robert Ross
10/2/2023
When every incident is chaos, the people problem gets overwhelming, and there’s no culture of improvement — engineers get burned out and seek greener pastures. That’s the cultural drain caused by incidents.
By Robert Ross
9/12/2023
FireHydrant provides massive benefits to enterprise-level customers through our API capabilities, streamlined collaboration, and centralized incident management hub. The addition of Multi Org makes FireHydrant the most complete solution for enterprises.
By Joel Smith
9/7/2023
Gimme 5 by FireHydrant is a look inside incident management at some of the world's most forward-thinking DevOps teams. In this episode, we talk with Alexia Loizides, Senior Manager of IT Service Management for payments platform Checkout.
By Stephanie Gonzalez
9/5/2023
We want to ensure we're adding to your workflow, not changing it. In this blog post, I'll delve into how our incident response technology works with other engineering tools by discussing some of our most popular integrations.
By Mike Lacsamana
8/24/2023
The total cost of incidents goes beyond the time spent resolving them. It also includes the cost of time that otherwise would’ve been focused on developing the next big thing. That’s opportunity cost.
By Robert Ross
8/24/2023
Downtime is just the beginning when it comes to the cost of poorly handled incidents. In this blog post, we explore how the first few minutes of an incident can set you up for success or sabotage — and how to ensure the former.
By Robert Ross
8/16/2023
In this blog post, we’ll talk about two incident management structure models — distributed and centralized, including the pros and cons of each, and examples of what each structure looks like in our community.
By Robert Ross
8/8/2023
Custom fields empower you to tailor FireHydrant to your organization's specific needs and capture essential incident details. Track critical states, involved parties, resolution specifics, messages, and more, all aligned with your unique workflows.
By Chris Kelly
7/27/2023
Analyst firm Enterprise Strategy Group conducted an in-depth evaluation of the costs associated with poor incident management practices and found that FireHydrant reduces the cost of incidents significantly.
By Robert Ross
7/26/2023
This post explores how to align platform and product engineering teams by implementing business value proxy metrics and using incidents to inform them.
By Gonzalo Maldonado
7/20/2023
Incident severity helps responders and stakeholders easily understand the impact of the incident, and set expectations for the level of response effort. Both of these help you fix the problem faster ... but first, you have to ensure severity is being set.
By Mike Lacsamana
7/5/2023
Viewers and collaborator roles upgrade FireHydrant RBAC to give you more control – and your team more visibility
By Joel Smith
6/29/2023
Designed to prioritize data privacy and provide greater oversight of sensitive incidents, Private Incidents give you more flexibility and control when it comes to incidents involving data security or legal matters.
By Joel Smith
6/22/2023
Organizing everyone involved in an incident can be more complicated than mitigating the incident itself. But there are processes you can put into place that will draw boundaries around who does what during an incident and set your stakeholders at ease.
By Robert Ross
6/20/2023
We're making it easier to manage complexity across a set of incidents. You can coordinate efforts across incidents with the same root cause or break down complex incidents into manageable work streams.
By Joel Smith
6/14/2023
We used to see multiple incident declarations exceed our 3-second target each day. After this update, it became rare to see any at all.
By David Celis
6/1/2023
Cycle time is how long it takes to move through each phase of an incident, from declaration all the way through resolution. Cycle time can help you evaluate the health of your incident response efforts and make improvements in the areas you can control.
By Jouhné Scott
5/31/2023
We’re making it even easier for teams to automate incident response. The moment a monitoring tools smell smoke, you can have an incident opened before you blink. Teams can now create decisive rules for triggered alerts in their favorite monitoring tools.
By Joel Smith
5/18/2023
Customer-facing status pages help companies efficiently acknowledge the concerns of their customers, building trust and establishing a single source of truth for information. Here are three best practices to keep in mind when creating yours.
By Daniel Condomitti
5/10/2023
Although we can’t control how long it might take to mitigate an incident, we can exercise a great deal of control over how quickly and prepared we get to the scene of the problem. We call that phase of the incident lifecycle “assembly time.”
By Robert Ross
5/4/2023
Incident metrics can give you insight into the success and growth of your incident response program and help you discover patterns in the causes and costs of incidents. And getting started is probably easier than you think.
By Jouhné Scott
5/2/2023
Keep a record of all your incidents, even if they happen too fast to document. Retroactively create incidents in FireHydrant without firing any Runbook automation – even if the incident has already been resolved.
By Joel Smith
4/27/2023
Incidents are expensive — and only getting more so. Clearly, there’s an advantage to reducing the amount of time it takes to resolve incidents. With this in mind, we analyzed 50,000 incidents and found were two clear ways to decrease mean time to resolve.
By Chris Kelly
4/18/2023
Documenting and training your team on your incident response processes is essential to ensuring a coordinated and efficient response effort. And training sessions, or game days, as they’re sometimes called, are one way to get everyone up to speed.
By Jouhné Scott
4/11/2023
There are incremental steps you can take to implement and then mature your approach to service-based incident response. In this blog post, we’ll talk about three approaches you can take based on your program’s maturity level.
By Chris Kelly
4/4/2023
By Robert Ross
3/24/2023
Assigned roles help teams spring into action after an incident is declared. This post explores what roles you should consider for your response plan, based on the size of your organization and your team’s incident response maturity level.
By Carissa Zukowski
3/21/2023
By Joel Smith
3/21/2023
Collaboration is essential to running effective, learnings-filled retrospectives. FireHydrant’s new retrospective commenting makes it easier for teams to create accurate, thorough retros, together.
By Joel Smith
3/9/2023
Skipping the retro shouldn’t be an option. Ditch the one-size-fits-all process to ensure that this important step is held at the end of every incident. Here’s how to make it happen.
By Jouhné Scott
3/7/2023
Incidents provide an unparalleled opportunity to learn about your people, processes, and products under pressure. In this post, we’ll tell you how to ensure your team isn’t letting these opportunities for learning go to waste.
By Jouhné Scott
3/2/2023
AWS Marketplace + FireHydrant: your path to easier compliance, consolidated spend, and faster procurement.
By Melissa Strauss
2/28/2023
We’re all looking to maximize every dollar spent, every hire made, every hour logged. But there’s one cost center you might not be thinking about — incident management. This post explores the explicit and implicit costs associated with incidents.
By Robert Ross
2/14/2023
Automatically measure MTTR, impacted infrastructure, task completion, and more with new incident analytics.
By Dylan Nielsen
1/24/2023
Panic takes time and energy away from swift incident response, leading to second-guessing, a higher likelihood of mistakes, and analysis paralysis. Here are three tips to minimize it.
By Malcolm Preston
1/18/2023
By automating some rote parts of incident response, you reduce decision fatigue and help responders get to solving the problem faster with less stress. In this post, we talk about three areas of the incident response process that are prime for automation.
By Robert Ross
1/3/2023
FireHydrant received three G2 Winter 2023 awards — High Performer, a High Performer in the Enterprise category, and a High Performer in the United Kingdom. We are honored to be recognized by G2 because these awards are based on customer reviews.
By Robert Ross
12/21/2022
Using anonymized data from 50,000 incidents, the Incident Benchmark Report reveals insights into the when, what, who, and how behind incidents and highlights behaviors that correlate to faster response times.
By Robert Ross
12/15/2022
In this post, we’ll dig into the difference between a bug and an incident, why alignment on how they are defined matters, and how to ensure you’re still learning from the issue, even if it’s “just a bug.”
By Jouhné Scott
12/7/2022
This post explores how we built FireHydrant in a way that allows us to rapidly build and deploy integrations to help our product fit into responders’ workflows and not vice versa.
By Robert Ross
11/28/2022
In many cases, there are components that go into building and running an incident management tool that aren’t considered. These are the three most common ones.
By Ryan McDonald
11/8/2022
Incidents can take many forms. How you respond to the incident will vary based on the impact of the incident. And that’s where severity comes into play.
By Ryan McDonald
11/2/2022
Sweeping platform improvements give you more power, configurability, and insights across every phase of an incident – even when it’s over. Discover what’s new in Status Pages, Retrospectives, and Analytics.
By Dylan Nielsen
10/24/2022
FireHydrant was recently featured in two industry reports, proving that strategic investments in incident management pay off for companies of all sizes.
By Robert Ross
10/6/2022
Struggling with incident management? You're not alone. Adopting an incident management tool can help businesses simplify and conquer incident response challenges to increase efficiency and customer satisfaction while decreasing burnout.
By Mike Lacsamana
10/3/2022
FireHydrant's new Zendesk integration allows users to link Zendesk tickets with FireHydrant incidents to quickly assess customer impact, determine incident severity and. priority, and optimize stakeholder communications.
By Michelle Peot
9/15/2022
Say hello to the Service Dependency Graph – a visual representation of the upstream and downstream impacts of an incident or change to your infrastructure.
By Crystal Poenisch
8/18/2022
Using FireHydrant's newest SCIM 2.0 protocol you can now easily add and delete users with set role permissions and update groups.
By Max Tilka
8/16/2022
Use the FireHydrant Terraform provider to configure Runbooks, task lists, service dependencies, incident roles, and more.
By Michelle Peot
8/8/2022
We recommend a light touch when using required fields in your incident declaration process. Here are a few things to consider before rolling out updates.
By Dylan Nielsen
8/1/2022
Centralize your incident management playbooks and enforce consistent practices every time. Give every incident responder turn-by-turn navigation for working through incidents — all without leaving Slack.
By Dylan Nielsen
7/21/2022
The incident response experience on FireHydrant has been fully redesigned for more intuitive workflows. Anyone on your team can easily onboard into an incident and navigate the response process — and you can enforce best practices along the way.
By Dylan Nielsen
7/19/2022
Between 2022-06-23 20:25 and 022-06-24 21:39, FireHydrant experienced an incident resulting in customers being unable to authorize the FireHydrant Slack app. This is the incident retrospective.
By Jouhné Scott
7/7/2022
Let’s look at three mistakes I’ve made during those stressful moments during the beginning of an incident — and discuss how you can avoid making them.
By Robert Ross
6/29/2022
FireHydrant’s June releases deliver a more intuitive Slack app, increased Runbook automation and conditional logic, smarter retros, and more.
By Dylan Nielsen
6/27/2022
The first step in understanding how to shift from incident response to incident management is to define what those terms mean.
By Robert Ross
6/24/2022
There are a number of lessons I learned guiding weeks-long backcountry leadership courses for teens that I carried with me into my roles in incident management. In this blog post, I’ll share three that stand out.
By Ryan McDonald
6/21/2022
You can see big gains from small investments when it comes to incident management, and the fundamentals can be put in place without purchasing tools or hiring new staff. Here are three steps you can take to better incident management today.
By Robert Ross
6/9/2022
In this installment of our employee spotlight series on FireHydrant team members, we’d like you to meet Carissa Zukowski, the newest engineering manager on our product team.
By Alisha Ehrlich
5/31/2022
By taking some first steps away from being the hero, we can help our companies shift toward better incident management and improve things for our customers, for our teammates, and for ourselves.
By Malcolm Preston
5/25/2022
The industry and markets are volatile right now. More than ever, you should be focused on shipping great products, retaining engineers, and building trust with customers. The right incident management strategy can help you make strides in all three.
By Robert Ross
5/18/2022
FireHydrant has expanded its integrations portfolio to include Cisco's Webex Meetings video collaboration platform. Now users can automate Webex bridge creation directly from FireHydrant.
By Michelle Peot
5/17/2022
How to create effective SLOs and connect them with SLAs and SLIs.
By Robert Ross
5/10/2022
FireHydrant now supports incident data field mapping to Jira custom fields, including the most common epic ticket type and customer-defined fields.
By Michelle Peot
4/27/2022
Use service dependencies to define key relationships within your service catalog and unlock more time to respond to incidents.
By Max Tilka
4/26/2022
Use our new Google Docs integration to export incident data and work collaboratively on retrospectives, all while maintaining traceability back to your FireHydrant incident.
By Michelle Peot
4/26/2022
FireHydrant gives you a framework to run retrospectives. Now we're creating a better way to learn and analyze from retrospectives by guaranteeing consistent data and volume from your team.
By Dylan Nielsen
4/12/2022
A thoughtful incident management plan can help you avoid future security incidents and cut down your incident response time drastically.
By Robert Ross
4/5/2022
One of our core values at FireHydrant is continuous improvement. Our engineering team runs bi-annual hack weeks to create space for experimentation, optimization, and building things that we’re passionate about.
By Jouhné Scott
3/24/2022
We envision a world where all software is reliable, and today we’re making that vision more of a reality for small teams. Today, FireHydrant is pleased to announce our new Free Tier for small teams!
By Robert Ross
3/14/2022
Do you need a dedicated incident commander? We will explore what an incident commander is, what forms the role can take, and when you should consider the addition of a dedicated incident commander to your organization.
By Ryan McDonald
3/11/2022
We are introducing a better experience in Slack to view and manage all your tasks during an incident.
By Vinessa Wan
3/8/2022
In this post we'll explain the differences between Incident severity and Incident priority as well as detail out practical levels and summaries for both.
By Robert Ross
2/24/2022
The experience of creating runbooks has been redesigned to make it easier for you to see the most important information. Our updates also introduce the ability to clone a runbook by selecting “Copy” on a saved runbook.
By Vinessa Wan
2/17/2022
You can now route your incident tickets and follow-up work to remediation teams' Jira projects directly from FireHydrant, saving you valuable time and clean-up work
By Dylan Nielsen
2/15/2022
Operational Readiness Checklist adds a layer of accountability and resilience to improve your service catalog best practices. Learn more to help improve your service adoption and incident response.
By Ally McKnight
2/11/2022
Starting today, incident and retrospective data that lives inside FireHydrant is now easier than ever to export to your Confluence account.
By Dylan Nielsen
1/26/2022
FireHydrant is now offering private incidents. This will allow engineering teams to collaborate with their security and compliance counterparts on a shared platform.
By Vinessa Wan
12/13/2021
A code freeze is intentionally halting changes to your codebase and environments in an effort to reduce the risk of an outage.On the surface, pausing on deployments feels like a logical solution to preventing incidents. Unfortunately, this isn't the case.
By Robert Ross
11/11/2021
Now available, FireHydrant users can spin up a private Slack channel to manage incidents
By Julia Tran
10/26/2021
Today, we are happy to announce the launch of Service Catalog to help you better manage, query, and learn about the services that exist in your infrastructure.
By Julia Tran
10/6/2021
FireHydrant is proud of our leadership and we want to highlight our awesome team of engineering managers. Meet Jouhné Scott!
By The FireHydrant Team
10/5/2021
Productivity revolves around quality. A Service Catalog helps promote this quality. So as your company strives to move faster, make sure quality moves with you.
By Max Tilka
10/1/2021
Reliability is not a metric that engineering alone controls, everyone in the business has a substantial stake in the reliability your customers feel.
By Robert Ross
9/30/2021
Learn more about our new plugin with Backstage
By Julia Tran
9/14/2021
Our engineer Christine Yi's perspective on contributing to an open source project with the Backstage and FireHydrant plug in and the three key values she learned
By Christine Yi
9/14/2021
Learn some of the basics around building a service catalog and our philosophy around this growing space.
By Max Tilka
9/2/2021
Learn about what's new and improved with FireHydrant, and what you can leverage for your team.
By Julia Tran
9/2/2021
FireHydrant is proud of our leadership and we want to highlight our awesome team of engineering managers. Starting off, we have Ally McKnight!
By The FireHydrant Team
8/31/2021
By Julia Tran
8/31/2021
Chaos engineering is an essential part of creating an effective incident management system and implementing processes that can help keep you in control when real chaos threatens your code.
By Robert Ross
8/24/2021
This is a quick primer to get started in Site Reliability Engineering if you're interested in becoming a Site Reliability Engineer (SRE).
By Robert Ross
8/16/2021
We envision a world where all software is reliable, and we’re on a mission to help every company that builds or operates software get closer to 100% reliability. Today, we’re thrilled to announce that we’ve raised $23 million to help us further our goal.
By Robert Ross
8/10/2021
Lessons learned from the front line that you actually immediately use in your incident management process.
By Robert Ross
7/15/2021
We're using MirageJS to enable front-end and back-end teams to develop features asynchronously, without obstacles.
By Hilary Beck
6/17/2021
We're over MTTR(esolution), but have you thought about MTTR(etro)?
By Robert Ross
6/10/2021
In May we released integrations with Checkly and Google Meet.
By Julia Tran
5/27/2021
Four things to consider when evaluating incident management platforms--from whether you have the culture and process to support a potential tool, to understanding your pain points, to knowing which key stakeholders to involve.
By Robert Ross
5/26/2021
Learn more about our integration with Checkly, an API and E2E monitoring platform
By Julia Tran
5/21/2021
Learn more about our integration with Google Meet
By Julia Tran
5/21/2021
Our panel discussion, "WTF is Incident Management," generated some great insight from a group of very experienced industry professionals.
By Megan Moore
5/17/2021
Failover Conf 2021 offered great discussions about reliability practices, concepts, and culture.
By Megan Moore
5/7/2021
Learn more about how incident tags can help you store more metadata and about our new customizable Slack incident modal.
By Julia Tran
4/23/2021
Building custom Slack commands is easy! You can run these commands directly from Slack to retrieve up-to-date information about your incident management process.
By Megan Moore
4/15/2021
We won an award! The MIM Awards recognize and reward effective Major Incident Management within the global IT Major Incident Management sector - and we won the 2020 Major Incident Software Innovation of the Year!
By The FireHydrant Team
4/8/2021
Announcing the first annual FyreHydrant Festival and the 2021 line-up
By Megan Moore
4/1/2021
Here are our latest product updates from March - now it's easier than ever to customize FireHydrant.
By Dylan Nielsen
3/31/2021
To celebrate Women's History Month and International Women's Day, we'll be spotlighting the Women of FireHydrant - this post is about Hannah Maguire, who is a business development representative.
By The FireHydrant Team
3/31/2021
Using the Crystal programming language, you can share developer tools quickly and easily. FireHydrant's Backend Engineer extraordinaire, Jon Anderson, walks us through the steps of testing shell commands with the CLI.
By Jon Anderson
3/29/2021
In this video, FireHydrant CEO and Co-Founder, Robert Ross, shares his thoughts and experience on why putting your APIs first can be a game-changer for your business and how it can pay dividends in the long haul.
By The FireHydrant Team
3/10/2021
Alert fatigue can not only cost not only cause more errors and financially impact your business but can also be detrimental to your health. This post goes over how alert fatigue manifests and some ideas on how to combat it,
By Robert Ross
3/9/2021
We had a great time at DeveloperWeek Virtual 2021 a few weeks ago on February 17-19, 2021. The event was jam-packed with great speakers, roundtable discussions, workshops, and more - and we had a lot of fun meeting some of the 5000 attendees.
By Kate Stowell
3/4/2021
We've made some exciting updates to the platform that makes creating Runbooks easier for new users, we spoke at Hashitalks and Developer Week, plus completely updated our website!
By Dylan Nielsen
2/26/2021
We've released more powerful analytics filtering so that you can drill down into your data even further. Here are some ideas on how to best get a handle on what's available.
By Dylan Nielsen
2/26/2021
Between 2021-02-05 00:20 and 2021-02-05 02:44, FireHydrant experienced an incident resulting in delayed runbook execution steps (Slack channel creation, etc) and intermittent availability issues on app.firehydrant.io. This is our incident retrospective.
By Daniel Condomitti
2/23/2021
We've been giving the FireHydrant brand a little nip tuck to meet the needs of our customers and future customers. Here's an update on the journey so far.
By Joanna Lin
2/23/2021
Business Insider looked at a broad range of attributes, including the strength of the founding team; the investors and their caliber; valuations, recent and total funding based on estimates from PitchBook; and the product or service the startup offers.
By The FireHydrant Team
2/13/2021
In any other job, conducting a postmortem means someone perished. Let's switch to a phrase that lessens the gruesomeness of software incidents. I wanted to provide some ideas that your organization could possibly run with as a replacement to “Postmortem.”
By Robert Ross
2/10/2021
We've had a lot of product updates this month. Check out our integrations with Opsgenie and VictorOps, new templates for incident types, and many other small improvements
By Dylan Nielsen
1/28/2021
Incidents are inevitable, and the reality is some of them are inevitably going to repeat themselves. Common incident types were slightly burdensome for our customers, so we're announcing an easy way to declare incidents using templates.
By Robert Ross
1/27/2021
Venture-capital firms in 2020 pumped $5.8 billion into New York technology startups. Companies developing risk-management, artificial intelligence, and machine learning technologies are among those getting the biggest shares of the investments.
By The FireHydrant Team
1/27/2021
We all know it: You expect your software tools to work every time, all the time. Let's do better this year - there’s no better time than now to dedicate effort to fireproofing your software.
By Robert Ross
1/19/2021
2020 was, needless to say, not the best. Looking on the brighter side, this past December, FireHydrant turned 2, and in spite of it all, we grew quite a bit. See how we fared in 2020.
By The FireHydrant Team
1/8/2021
This is the first in a series of interviews with experts about reliability, incident response, and other related topics. We sit down with Jeff Smith from Centro to ask for his thoughts on reliability and incident management.
By The FireHydrant Team
12/17/2020
We made it to our final episode! Thank you to everyone that tuned in and watched Bobby get a Terraform provider up and running. We hope you enjoyed watching me through the good, bad, and ugly these past 20 or so hours.
By Robert Ross
12/4/2020
KubeCon + CloudNativeCon North America 2020 Virtual was held online on November 18th to 20th. We had a lot of fun attending and saw a lot of great talks. Read our wrap-up below.
By Rich Burroughs
11/24/2020
In episode 9 of Throughput Thursdays, we work to configure a Runbook and get it to work! Watch part 1 of our two-part finale below to see what happens.
By Robert Ross
11/20/2020
In episode 8 of Throughput Thursdays, we break down all the logically grouped pieces into their own interfaces and create an interface on our client that can return.
By Robert Ross
11/13/2020
In episode 7, we create resources for managing teams and severities through the Terraform provider, which means we now can now manage more of users’ FireHydrant configurations with code.
By Robert Ross
10/30/2020
HashiConf Digital October 2020 was the second HashiConf to be held online due to the coronavirus pandemic. It was held on October 14 and 15 on HashiCorp’s digital event platform. Read our take om HashiConf Digital October 2020.
By Rich Burroughs
10/27/2020
In Episode 6, we update our Terraform resource for FireHydrant functionalities and create a data source for FireHydrant services. This allows us to pull services from a list and link them to functionalities. Linking resources like this lets us do a lot of cool things with Terraform.
By Robert Ross
10/23/2020
At FireHydrant, we recently began to replace our usage of thunks with Sagas to handle our data fetching. Read how we moved from Redux Thunk to Redux-Saga.
By Mandy Mak
10/21/2020
Do you like spooky stories about incidents? If you do, you should check out the new streaming series called Dastardly Disasters on Snyk’s Twitch channel. The first episode aired on October 16 and featured FireHydrant’s CEO Robert (Bobby) Ross, Alyssa Miller from Snyk, and Jacob Plicque from Gremlin, sharing stories about incidents they encountered in their careers.
By Rich Burroughs
10/20/2020
A lot can happen in a month: we also released conditions in FireHydrant Runbooks, premiered a fun video at Chaos Conf, filmed Throughput Thursdays on Twitch, and hosted a webinar, but wait, there’s more!
By Dylan Nielsen
10/20/2020
We’re pretty sure using a real incident to test a new response process is not the best idea. So, how do you test your process ahead of time? Learn how to use chaos engineering principles to stress test your incident management process.
By The FireHydrant Team
10/15/2020
That’s a wrap! We had a great time at Chaos Conf last week - from great presentations to engaging conversations in the Slack community - we were glad we could be a part of it.
By Joanna Lin
10/13/2020
In this episode of Throughput Thursdays, we test our Terraform resources. If you missed it, you can watch it here.
By Robert Ross
10/9/2020
FireHydrant’s Slack integration is a great way to speed up your incident response, especially if FireHydrant Runbooks is automatically creating channels in your Slack workspace for each incident.
By Joanna Lin
10/7/2020
In episode 4, we were able to achieve creating two full-blown Terraform resources for FireHydrant environments and functionalities. While simple resources, they unlock a lot of power that did not exist previously for teams that want to document their infrastructure using Terraform.
By Robert Ross
10/2/2020
We’ve made your favorite FireHydrant feature, FireHydrant Runbooks, even more powerful with conditions - a way to build custom logic into your runbook automation.
By Dylan Nielsen
10/1/2020
Our release of conditions in FireHydrant Runbooks has made it easier for teams who rely on email to communicate with key stakeholders or a distribution list.
By Joanna Lin
10/1/2020
It’s no secret that the cloud has become the enterprise technology hero of 2020. COVID-19 ensured any kind of backburner considerations shot to the front of IT stakeholders’ minds.
By The FireHydrant Team
9/30/2020
Things are gearing up in our preparations for Chaos Conf by Gremlin. We're sponsoring the conference -- will we see you there?
By Joanna Lin
9/28/2020
Cloud-computing startups have landed new investments and customer accounts during the coronavirus pandemic as many companies have accelerated cloud-related projects to keep ahead of the competition.
By The FireHydrant Team
9/25/2020
In episode 3, we built a flexible API client for our Terraform provider that implements a really simple interface. We also wrote some simple but effective tests and replaced the original cruft in the provider code with our new API client.
By Robert Ross
9/25/2020
Going API first will save you headaches in the long run. This post shares why choosing to go API first from Day 1 will be a game-changer for your business, and the decisions we made at FireHydrant to do this.
By Robert Ross
9/21/2020
In Episode 2, Bobby is live in Cape Cod, sitting on a dock about 4 inches from the edge of a lake. Last week we built a skeleton of a Terraform provider. Now we’ll get the provider to create and delete resources, like services in FireHydrant.
By Robert Ross
9/18/2020
Tori Crawford, one of our engineers, walks through some ways that you can get immersed in unfamiliar code. She gathered input and insights from the rest of the FireHydrant team to create this quick playbook on best practices that will make tackling any new codebase easier.
By Tori Crawford
9/16/2020
This September, check out our new and improved analytics experience, new Slack app home, and many more updates.
By Dylan Nielsen
9/14/2020
In Episode 1, we started out the Terraform provider with a simple data resource against the FireHydrant API. We were able to successfully retrieve information about a single service and display its name in our terminal!
By Robert Ross
9/11/2020
DevOpsDays Chicago 2020 was held online on September 1. This is our wrap-up of DevOpsDays Chicago
By Rich Burroughs
9/3/2020
Almost everyone knows that working with third-party APIs can be challenging. Sometimes the errors happen unexpectedly. Sometimes the error information that you receive is inaccurate. While most people feel these pains acutely, I’d like to share how we answer these challenges at FireHydrant and how it’s helped us avoid headaches and stress.
By Mark Starkman
9/2/2020
KubeCon + CloudNativeCon Europe 2020 Virtual happened online, August 18-20. It was the first virtual KubeCon, due to the coronavirus pandemic. I was happy to attend, although this was the second straight virtual conference I’ve participated in that ran on Amsterdam time.
By Rich Burroughs
8/26/2020
This past month, we’ve been committed to simplifying the platform while making some of our most critical workflows more powerful than ever. Here you’ll find some highlights over the last month.
By Dylan Nielsen
8/4/2020
Incident response doesn’t only happen in Slack, so today we’re happy to announce our integration with Zoom to create incident bridges automatically. Now a Zoom meeting can be added with fully customizable titles and agendas based on your incident details.
By Dylan Nielsen
7/28/2020
Fire hydrants usually have a firehose hooked up, and do we have a firehose of updates this July. We’ve been focused on making FireHydrant simpler to use and more deeply integrated with existing workflows to make managing your complex systems easier.
By Robert Ross
7/17/2020
Here's a set of changes to the incident and retrospective pages to further simplify the incident command center.
By Dylan Nielsen
7/6/2020
It's easier than ever to turn PagerDuty alerts into FireHydrant incidents in one click.
By Dylan Nielsen
7/6/2020
Communication is one of the hardest things to do well while responding to incidents. At FireHydrant, we’ve focused on helping people communicate well within their teams when responding to incidents, and also after the fact during post-incident reviews. Here's our latest product release - Status Pages
By Rich Burroughs
7/2/2020
The first HashiConf Digital event was held on June 22-24, online. This is our take on the event.
By Rich Burroughs
6/30/2020
We like to have fun when we build our product - read about how Rebecca Black's "Friday" snuck its way into our codebase.
By Robert Ross
6/24/2020
Due to the complexity of systems, it’s no longer a matter of “if” our systems will fail but “when”. To manage expectations for when our systems do fail, we can look no further than our Service Level Agreement.
By Mike Lacsamana
6/8/2020
We conducted an On-Call and COVID-19 survey from April 8 to April 27, 2020 and received 141 anonymous responses. Here are the results.
By Rich Burroughs
6/2/2020
A technology adventure: First the audio wasn’t working correctly on Zoom, then Google Meet. It was like a case study in what FireHydrant is designed to do — help companies manage incidents and recover more quickly when things go wrong with their services.
By The FireHydrant Team
5/20/2020
For the past year we've seen over 50,000 hours of incidents, 20,000 runbook actions automated, and 10 million deploy events, and we're happy to announce our $8M Series A led by Menlo Ventures.
By Robert Ross
5/20/2020
When Bobby couldn't find the tools he needed to effectively tackle incidents, he built one. Now announcing FireHydrant's $8M Series A.
By The FireHydrant Team
5/20/2020
Deserted Island DevOps was held on April 30, 2020, in the game Animal Crossing: New Horizons. It was the first tech conference held in Animal Crossing, as far as I know, and was streamed live on Twitch.
By Rich Burroughs
5/4/2020
Failover Conf was held online on April 21, 2020 hosted by Gremlin. in this post, Rich Burroughs shares some of his thoughts on the event and the talks he was able to catch.
By Rich Burroughs
4/24/2020
Bobby shares his new hobby: making craft cocktails. In this post we’re going to make a classic: The Old Fashioned.
By Robert Ross
4/21/2020
We sit down with experts to get their insights on handling on-call teams during COVID-19. They all have different viewpoints, but some themes emerge, like managing alerts, having empathy, and practicing self-care.
By Rich Burroughs
4/16/2020
Learnings from Netflix from an excellent talk from Lorin Hochstein from Spinnaker Summit 2010 called “OOPS! Learning from Surprise at Netflix.”
By Rich Burroughs
4/6/2020
We sit down with Alex Hidalgo to chat about his new book.
By Rich Burroughs
4/2/2020
Check out our latest release - an update to our ticket and task tracking features in FireHydrant.
By Dylan Nielsen
3/17/2020
Here are 3 postmortem practices that embrace a blame-free culture.
By Mandy Mak
3/9/2020
How to make the most of FireHydrant's Service Catalog.
By The FireHydrant Team
1/31/2020
3 practical ways for CS and Engineering teams to work better together.
By The FireHydrant Team
1/15/2020
How to get past the nonsense and look at problems differently.
By Robert Ross
11/12/2019
Just around 9:45 a.m. Pacific Time on February 28, 2017, websites like Slack, Business Insider, Quora and other well-known destinations became inaccessible. For millions of people, the internet itself seemed broken.
By The FireHydrant Team
10/31/2019
Announcing our most powerful feature yet: FireHydrant Runbooks is a better way to automate your incidents.
By Robert Ross
10/17/2019
Why distributing your on-call workload is critical.
By Daniel Condomitti
10/9/2019
You like living on the edge, life is fun on the edge until the edge is a macOS major update. Then you use vibrantly colorful words, some that your dead ancestors heard, all because your development environment now doesn’t work in spectacular fashion.
By Robert Ross
10/8/2019
A story about open source.
By Robert Ross
9/22/2019
Redux powers our global state at FireHydrant, one of the things we use most heavily is the ability to let redux store our API errors to handle failure states on the UI. See how we're using Redux to power our global state at FireHydrant.
By Dylan Nielsen
9/16/2019
Check out our latest integration with AWS CloudTrail.
By Daniel Condomitti
9/16/2019
How we updated our Kubernetes integration at FireHydrant.
By Robert Ross
8/28/2019
Announcing our latest integration with Statuspage.io.
By Robert Ross
8/22/2019
See how service catalog, incident management, and incident communications come together in a live demo.
Get a demo