Sticking to Your SLAs with FireHydrant Runbooks
Due to the complexity of systems, it’s no longer a matter of “if” our systems will fail but “when”. To manage expectations for when our systems do fail, we can look no further than our Service Level Agreement.

By Mike Lacsamana on 6/8/2020

In today’s world, systems are increasingly becoming more and more complex. Due to this complexity, it’s no longer a matter of “if” our systems will fail but “when”. To manage expectations for when our systems do fail, we can look no further than our Service Level Agreement.
As defined by Google, a Service Level Agreement, or an SLA, is a “business-level agreement which defines the service availability for a customer and the penalties for breaking that availability”.
SLAs are integral to any service-based industry. Defining clear SLAs help us set customer expectations while also affording our support and engineering teams added time to tackle issues as they arise. Given the importance of SLAs, how can we ensure we’re maintaining our SLAs in a way that affords our support and engineering teams the proper physical and mental capacity to mitigate the issue at hand?
To do this, we’ll simply need to create a new Runbook on FireHydrant.
You can think of Runbooks as our personal blueprint (or pre-configured steps) that will automatically execute either during an incident or when an incident is initially declared. This can range anywhere from creating a new ticket in JIRA to updating our Statuspages, letting us automate as much of our incident response process as we want to.
Using Runbooks, we’ll be able to post updates to our status page and/or notify our team to post updates to our status page, automatically.
This will allow our team to focus on the matter at hand while also having coordinated communication with our clients and/or internal teams; letting them know that we are working on the issue and therefore maintaining our SLA.
Let’s say we are running an eCommerce shop named Spurantics, and an incident just occurred where one of our key functionalities, add to cart, is fully down. Let’s also say for our SLA with our customers, we’re required to post an update every 20 minutes until the issue is mitigated.
Using a Runbook, we can first start by automatically posting the new incident to our public-facing status page the moment the initial incident occurs.
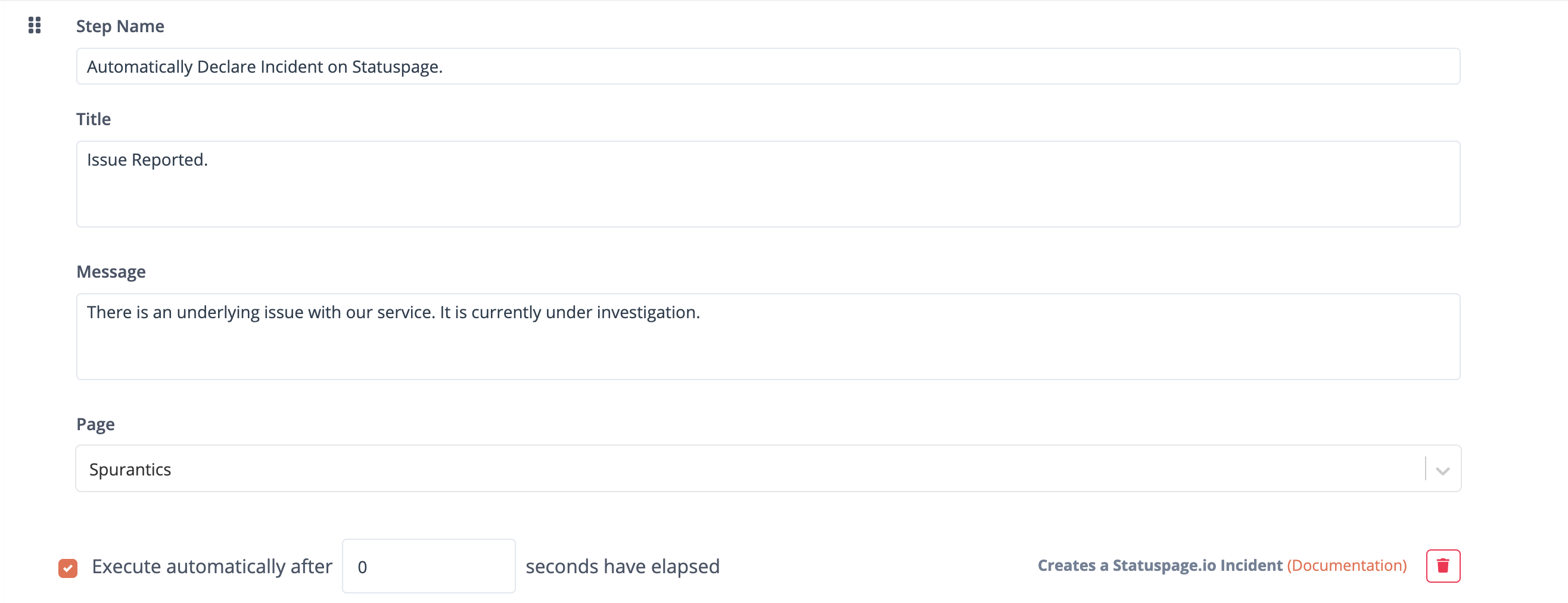
We can then manage our SLAs in two different ways.
Our first option would be to automatically post an update of the incident, every 20 minutes, to our public-facing status page. This would free up our team’s time to continue to work on the problem at hand until a more concrete update is available.
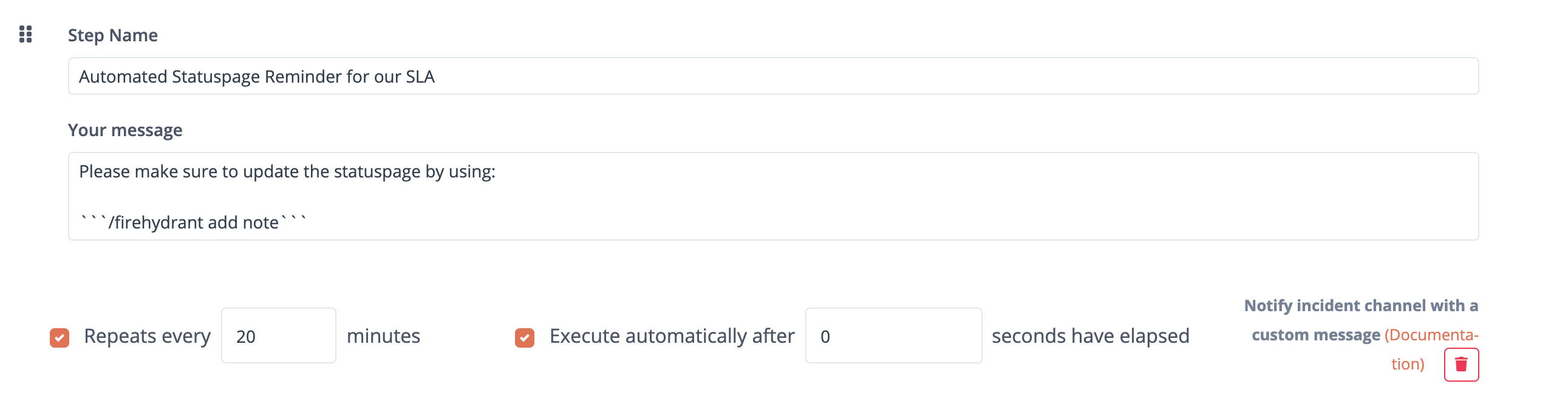
Our second option would be to send a reminder to our team, every 20 minutes, whether that be slack or email, to post an update to our public-facing status page. This would ensure our team is hitting our SLA while also allowing us to customize our updates as they come in.
From here, you’ll have the option to automatically execute this Runbook when a new incident is declared or attach this runbook to a current incident in progress.
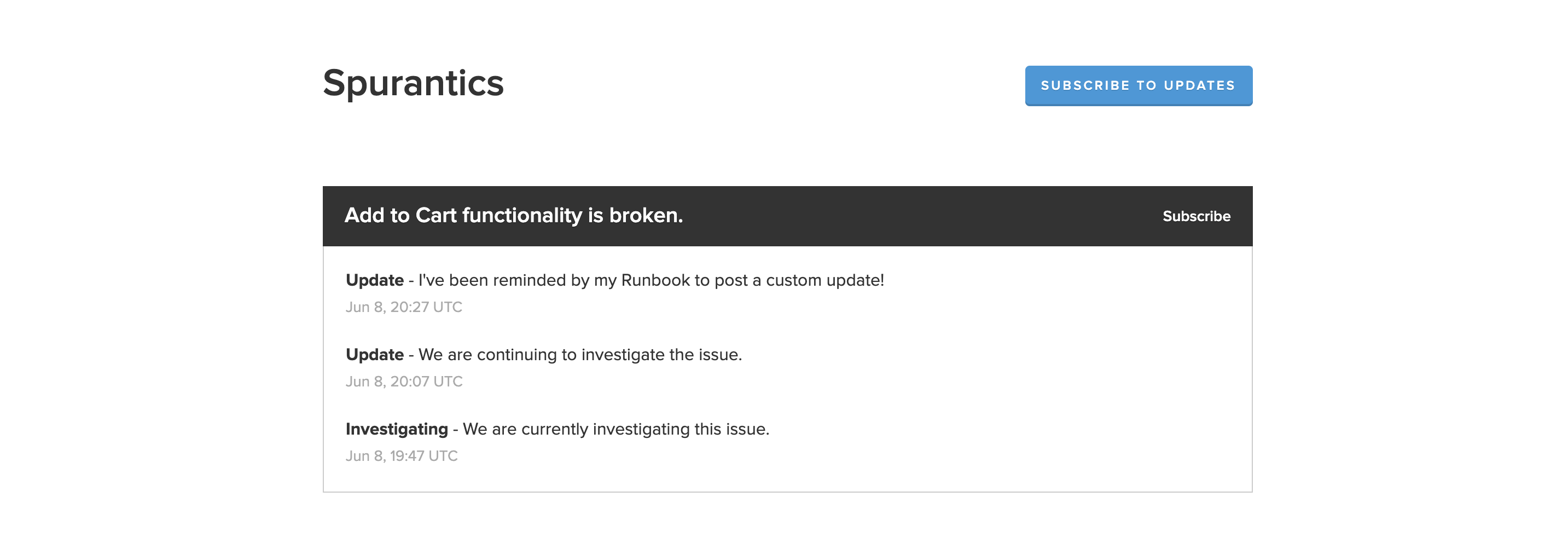
Thanks to FireHydrant’s Runbooks, we’ll now be able to stick to our SLAs and keep our clients happy while also granting our team the valuable time they need to solve the issue at hand with fewer distractions.
For more information on Status Pages, click here.
See FireHydrant in action
See how service catalog, incident management, and incident communications come together in a live demo.
Get a demo